Data Lake Foundation on AWS
Partner Solution Deployment Guide

August 2023
Dave May, AWS Integration & Automation team

| Refer to the GitHub repository to view source files, report bugs, submit feature ideas, and post feedback about this Partner Solution. To comment on the documentation, refer to Feedback. |
This Partner Solution was created by Amazon Web Services (AWS). Partner Solutions are automated reference deployments that help people deploy popular technologies on AWS according to AWS best practices. If you’re unfamiliar with AWS Partner Solutions, refer to the AWS Partner Solution General Information Guide.
Overview
This guide covers the information you need to deploy the Data Lake Foundation Partner Solution in the AWS Cloud.
A data lake is a repository that holds a large amount of raw data in its native (structured or unstructured) format until the data is needed. Storing data in its native format lets you accommodate any future schema requirements or design changes.
Increasingly, customer data sources are dispersed among on-premises data centers, software-as-a-service (SaaS) providers, APN Partners, third-party data providers, and public datasets. Building a data lake on AWS offers a foundation for storing on-premises, third-party, public datasets at low prices and high performance. A portfolio of descriptive, predictive, and real-time agile analytics built on this foundation can help answer important business aspects, such as predicting customer churn and propensity to buy, detecting fraud, optimizing industrial processes, and content recommendations.
This Quick Start is for developers who want to get started with AWS-native components for a data lake in the AWS Cloud. When this foundational layer is in place, you may choose to augment the data lake with independent software vendors and SaaS tools.
The Quick Start builds a data lake foundation that integrates AWS services such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Kinesis, Amazon Athena, AWS Glue, Amazon Elasticsearch Service (Amazon ES), Amazon SageMaker, and Amazon QuickSight. The data lake foundation provides these features:
-
Data submission, including batch submissions to Amazon S3 and streaming submissions via Amazon Kinesis Data Firehose.
-
Ingest processing, including data validation, metadata extraction, and indexing via Amazon S3 events, Amazon Simple Notification Service (Amazon SNS), AWS Lambda, Amazon Kinesis Data Analytics, and Amazon ES.
-
Dataset management through Amazon Redshift transformations and Kinesis Data Analytics.
-
Data transformation, aggregation, and analysis through Amazon Athena, Amazon Redshift Spectrum, and AWS Glue.
-
Building and deploying machine learning models using Amazon SageMaker.
-
Search by indexing metadata in Amazon ES and displaying it on Kibana dashboards.
-
Publishing into an S3 bucket for use by visualization tools.
-
Visualization with Amazon QuickSight.
The usage model diagram in the following figure illustrates key actors and use cases that data lake enables, in the context of key component areas that comprise the data lake. This Quick Start provisions foundational data lake capabilities and optionally demonstrates key use cases for each type of actor in the usage model.

The following figure illustrates the foundational components of the data lake and how they relate to the usage model. Using your data and business flow, the components interact through recurring and repeatable data lake patterns.

Costs and licenses
There is no cost to use this Partner Solution, but you will be billed for any AWS services or resources that this Partner Solution deploys. For more information, refer to the AWS Partner Solution General Information Guide.
Architecture
Deploying this Partner Solution with default parameters builds the following Data Lake Foundation environment in the AWS Cloud.
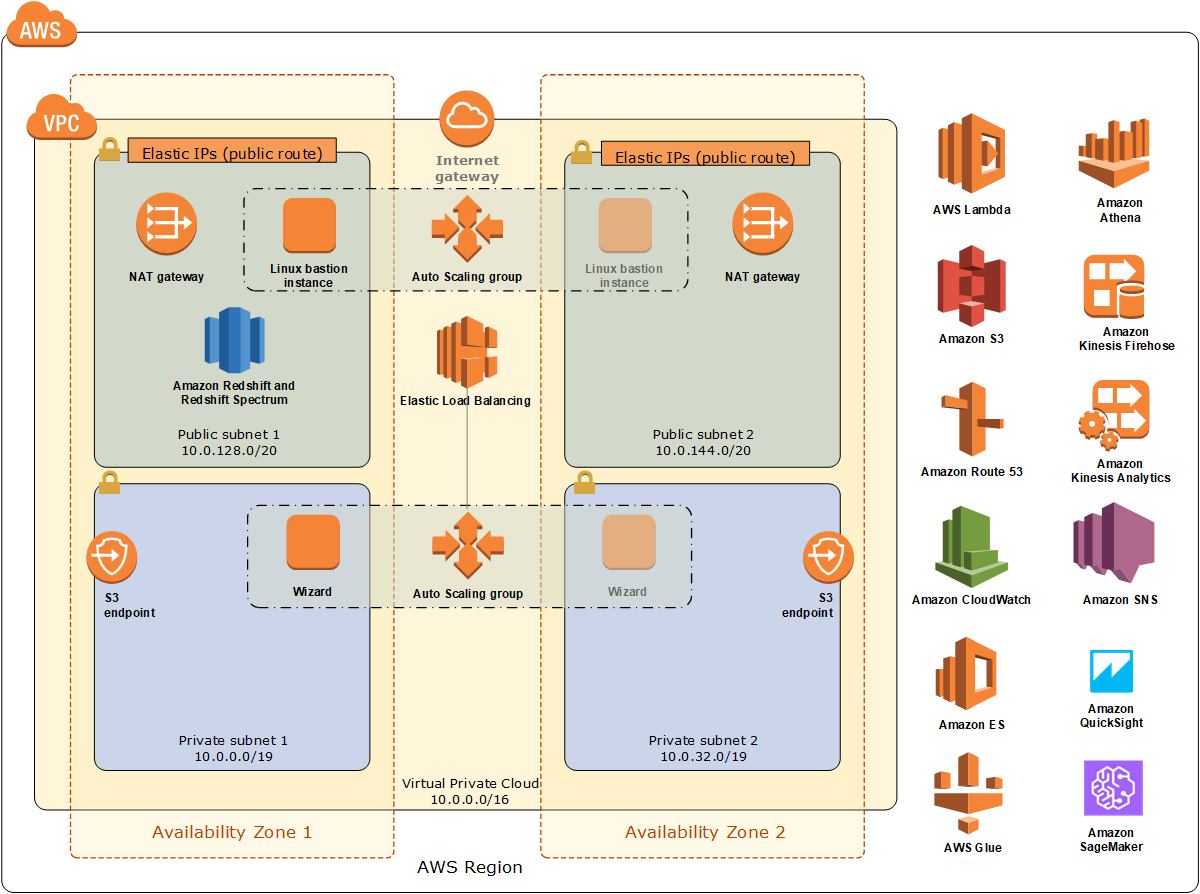
As shown in Figure 3, this Partner Solution sets up the following:
-
A virtual private cloud (VPC) that spans two Availability Zones and includes two public and two private subnets.*
-
An internet gateway to allow access to the internet.*
-
In the public subnets:
-
Managed network address translation (NAT) gateways to allow outbound internet access for resources in the private subnets.*
-
Linux bastion hosts in an Auto Scaling group to allow inbound Secure Shell (SSH) access to Amazon Elastic Compute Cloud (Amazon EC2) instances in public and private subnets.*
-
Amazon Redshift and Redshift Spectrum for data aggregation, analysis, transformation, and creation of curated and published datasets.
-
-
In the private subnets:
-
An Amazon S3 endpoint.
-
The Data Lake wizard.
-
-
AWS Identity and Access Management (IAM) roles to provide permissions to access AWS resources (for example, to permit Amazon Redshift and Amazon Athena to read and write curated datasets).
-
An Amazon SageMaker instance, which you can access by using AWS authentication.
-
Integration with other Amazon services, such as Amazon S3, Amazon Athena, AWS Glue, AWS Lambda, Amazon ES with Kibana, Amazon Kinesis, and Amazon QuickSight.
* The template that deploys this Partner Solution into an existing VPC skips the components marked by asterisks and prompts you for your existing VPC configuration.
The following figure shows how these components work together in a typical end-to-end process flow.
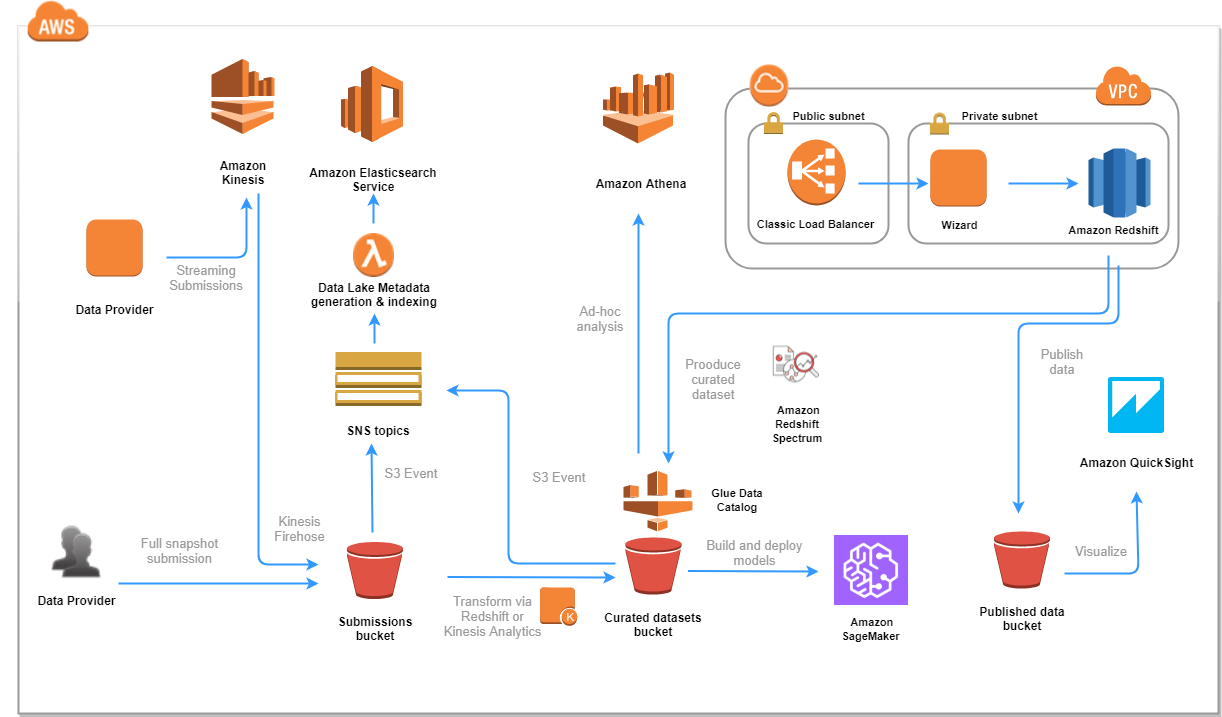
Deployment options
This Partner Solution provides the following deployment options:
-
Deploy Data Lake Foundation into a new VPC. This option builds a new AWS environment that consists of the VPC, subnets, NAT gateways, security groups, bastion hosts, and other infrastructure components. It then deploys Data Lake Foundation into this new VPC.
-
Deploy Data Lake Foundation into an existing VPC. This option provisions Data Lake Foundation in your existing AWS infrastructure.
This Partner Solution provides separate templates for these options. It also lets you configure Classless Inter-Domain Routing (CIDR) blocks, instance types, and Data Lake Foundation settings.
Predeployment steps
Ensure that the domain name in the DHCP options is configured, as explained in the Amazon VPC documentation. Provide your VPC settings when you launch the Quick Start.
Before you deploy this Partner Solution, we recommend that you become familiar with the following AWS services. (If you are new to AWS, see the Getting Started Resource Center.)
Deployment steps
-
Sign in to your AWS account, and launch this Partner Solution, as described under Deployment options. The AWS CloudFormation console opens with a prepopulated template.
-
Choose the correct AWS Region, and then choose Next.
-
On the Create stack page, keep the default setting for the template URL, and then choose Next.
-
On the Specify stack details page, change the stack name if needed. Review the parameters for the template. Provide values for the parameters that require input. For all other parameters, review the default settings and customize them as necessary. When you finish reviewing and customizing the parameters, choose Next.
Unless you’re customizing the Partner Solution templates or are instructed otherwise in this guide’s Predeployment section, don’t change the default settings for the following parameters: QSS3BucketName,QSS3BucketRegion, andQSS3KeyPrefix. Changing the values of these parameters will modify code references that point to the Amazon Simple Storage Service (Amazon S3) bucket name and key prefix. For more information, refer to the AWS Partner Solutions Contributor’s Guide. -
On the Configure stack options page, you can specify tags (key-value pairs) for resources in your stack and set advanced options. When you finish, choose Next.
-
On the Review page, review and confirm the template settings. Under Capabilities, select all of the check boxes to acknowledge that the template creates AWS Identity and Access Management (IAM) resources that might require the ability to automatically expand macros.
-
Choose Create stack. The stack takes about 30 minutes to deploy.
-
Monitor the stack’s status, and when the status is CREATE_COMPLETE, the Data Lake Foundation deployment is ready.
-
To view the created resources, choose the Outputs tab.
Troubleshooting
For troubleshooting common Partner Solution issues, refer to the AWS Partner Solution General Information Guide and Troubleshooting CloudFormation.
FAQ
Q. I deployed the Quick Start in the EU (London) Region, but it didn’t work.
A. This Quick Start includes services that aren’t supported in all Regions. See the pages for Amazon Kinesis Data Firehose, AWS Glue, Amazon SageMaker, and Amazon Redshift Spectrum on the AWS website for a list of supported Regions.
Q. Can I use the Quick Start with my own data?
A. Yes, you can.
Customer responsibility
After you deploy a Partner Solution, confirm that your resources and services are updated and configured—including any required patches—to meet your security and other needs. For more information, refer to the Shared Responsibility Model.
Feedback
To submit feature ideas and report bugs, use the Issues section of the GitHub repository for this Partner Solution. To submit code, refer to the Partner Solution Contributor’s Guide. To submit feedback on this deployment guide, use the following GitHub links:
Notices
This document is provided for informational purposes only. It represents current AWS product offerings and practices as of the date of issue of this document, which are subject to change without notice. Customers are responsible for making their own independent assessment of the information in this document and any use of AWS products or services, each of which is provided "as is" without warranty of any kind, whether expressed or implied. This document does not create any warranties, representations, contractual commitments, conditions, or assurances from AWS, its affiliates, suppliers, or licensors. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.
The software included with this paper is licensed under the Apache License, version 2.0 (the "License"). You may not use this file except in compliance with the License. A copy of the License is located at https://aws.amazon.com/apache2.0/ or in the accompanying "license" file. This code is distributed on an "as is" basis, without warranties or conditions of any kind, either expressed or implied. Refer to the License for specific language governing permissions and limitations.